
As we complete the final preparations before shipping our robot to Houston, I’d like to take a moment to reflect on some software topics from our last event at Greater Boston.
Odometry Tuning
With a new motorized hood to control, we had to rely on accurate vision and odometry data more than ever before. As I’ve discussed previously, we use an averaging system for odometry where the weight of the vision data vs. existing drive data is tunable (and also depends on the robot’s angular velocity). Tuning the gains for that algorithm is tricky in the shop, since defense and match strategy play a huge role in how quickly we need to maneuver and how much we’ll be pushed around between shots.
For example, we faced some very impressive defense in QM 38, which the odometry system wasn’t properly tuned to handle — the drive data drifted significantly from reality, and it didn’t adjust quickly enough when receiving vision updates. This resulted in several volleys of missed shots. I think I’ve now examined the log of this match for longer than the rest of the matches combined…
Based on data from QM 38, we were able to retune the odometry system before our next match. Using the replay feature of our logging framework, we could try a variety of gains and see how they would have performed if we ran them on the field. Here’s an example of the robot adjusting odometry based on vision data — the top shows the real calculations performed during a match, and the bottom shows a retuned system.
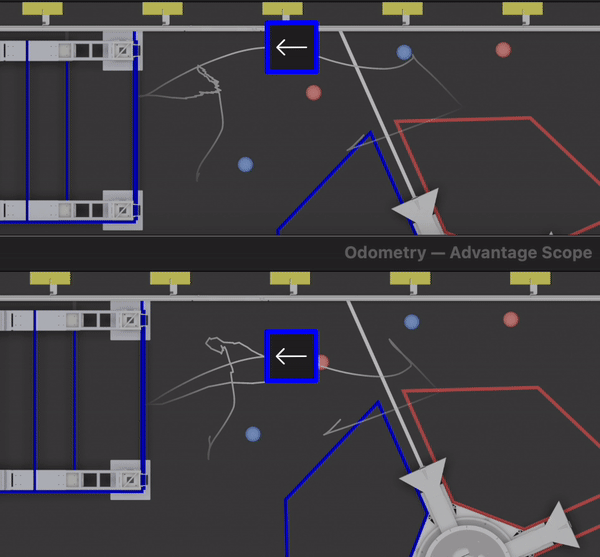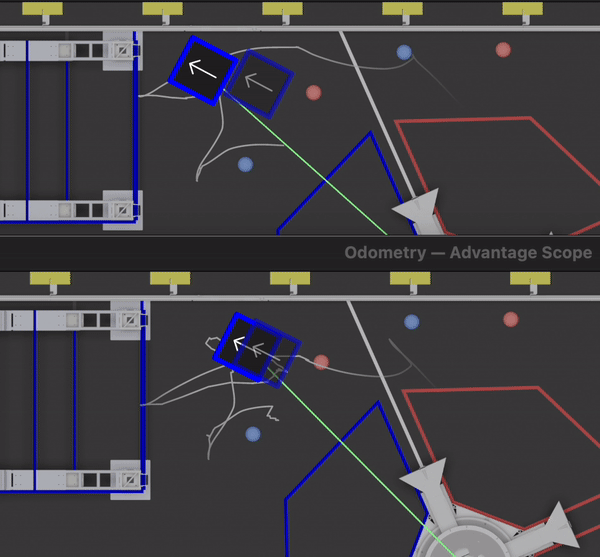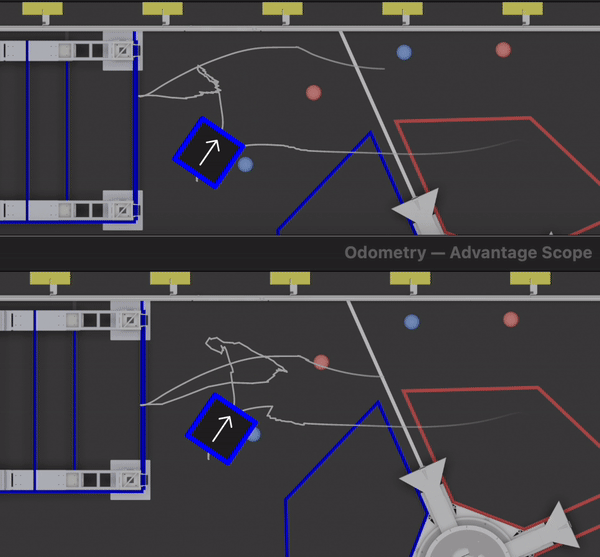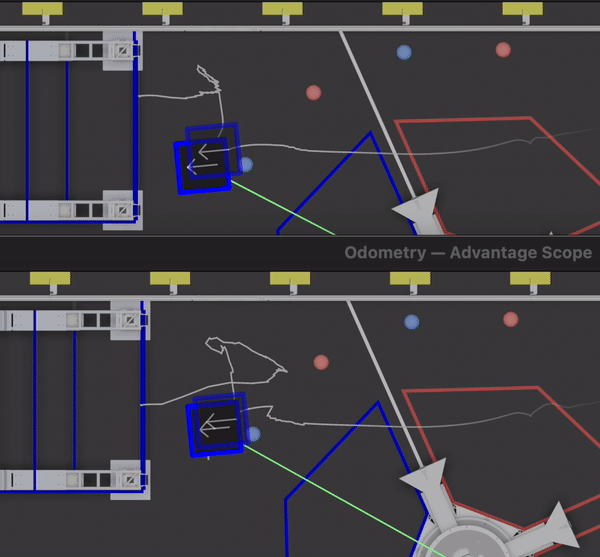
As we worked on refining the vision system based on log data, we also realized that it would be useful to visualize the raw corner positions (and top down translations) from the Limelight. The data was included in the log files, we just didn’t have a built in way to visualize it with Advantage Scope. After the event, we added a generic 2D point visualizer. We can now view visualizations like the one below using just a log file — no preprocessing or video editing required. The colored points show the corner data from the Limelight, and the white points are the top-down translations to each corner (the input data used for circle fitting).
We’re currently in the process of analyzing log data from the event to evaluate any other improvements we can make to the vision system (like better rejection of invalid targets).
A New Auto!
For playoffs, we deployed a new three cargo auto routine that picked up cargo from our partner 5563. We also ejected an opponent cargo into the hangar for good measure. Here’s an example of the full routine in action:
We had a large suite of auto routines prepared for the event (I believe @Connor_H would like me to say that there are technically “30” routines). However, this particular auto wasn’t one of them. As we had to write the full routine during lunch, simulation was essential in checking that the sequence would function correctly:
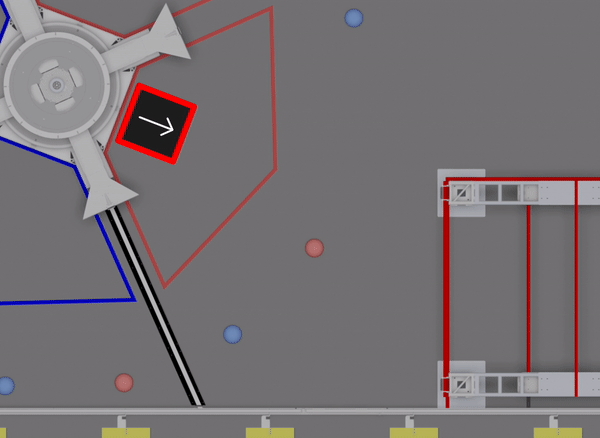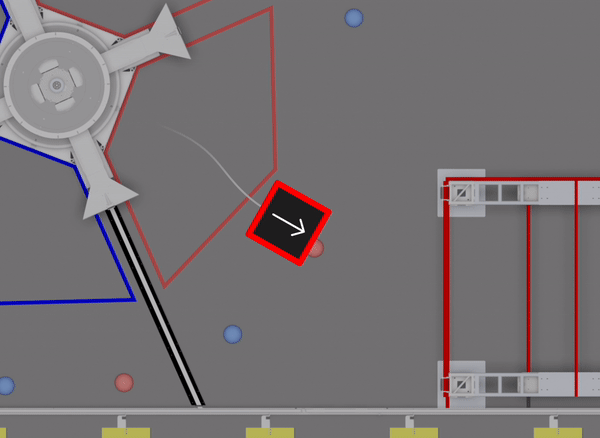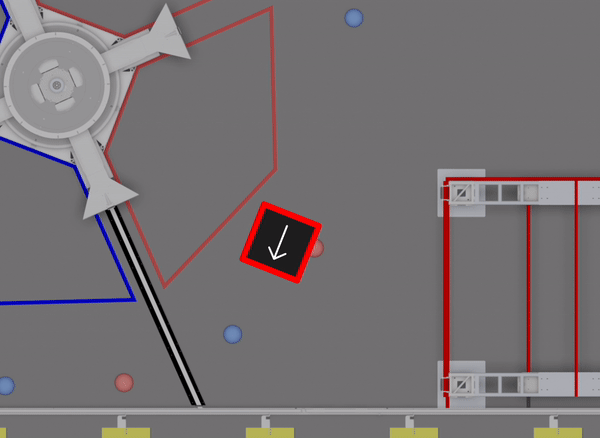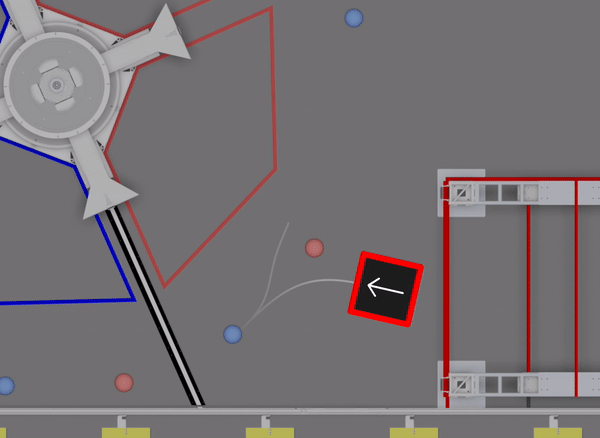
We’re continuing to explore options for new auto routines, and will have more details soon.
Log Statistics
As with our first event, we’ve compiled some fun statistics based on the robot’s log files. The detailed data is available in this document for anyone curious to dig deeper. I’d like to highlight this graph in particular, comparing a few statistics between our two events:
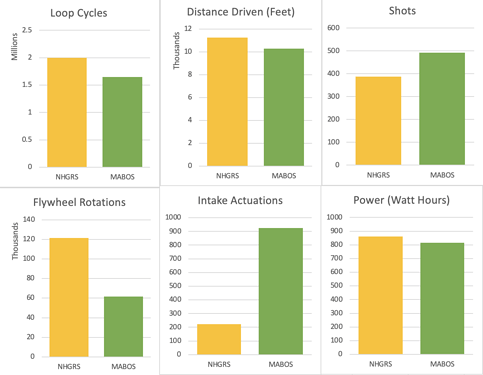
I think it’s fascinating to try to explain some of these comparisons. Our loop cycle, distance drive, and power usage were all similar. The shot count increased by 104, which is probably an accurate reflection of our increasing scoring ability (largely thanks to our new motorized hood). Intake actuations increased by a factor of four because we changed the operator control scheme — the intake automatically retracted when it wasn’t being used to avoid penalties. The oddest change to me is the decreased number of flywheel rotations. My best guess is that we just never ran it as much in the pit for testing. The majority of flywheel rotations happened off-field at Granite State, while the majority happened on-field at Greater Boston. I also enjoy examining the distance driven broken down by match:
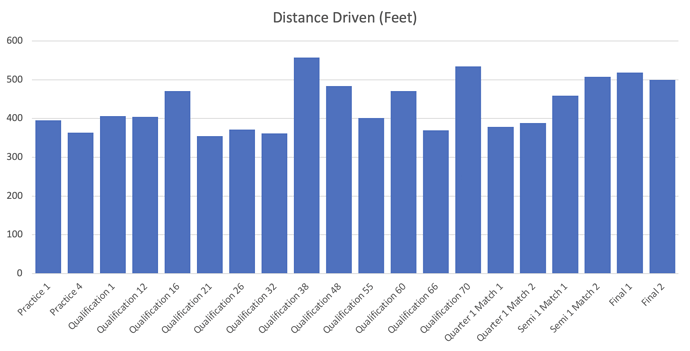
We can see that in QM 38 (with the heavy defense), we drove significantly farther than the preceding matches. The semi finals and finals also brought some heavy driving and rapid cycles, which is nicely reflected in the data.
In running this analysis, we replaced the count of hood actuations with a total measure of degrees traveled. Throughout the event, the hood moved 13867° (about 38.5 rotations). Here’s a useless statistic — that means the hood moved 0.06% as far as the flywheel. I’m so happy that we can finally find answers to important questions like this.
Battery Scanning
This is a feature that we added before Granite State but just forgot to mention. I guess it’s better late than never…
Now that we’re logging data from every match and practice session, we realized that it would be very useful to associate the battery in the robot to each log file. If we ever saw some suspicious behavior, we could test the battery more thoroughly or pull it out of our competition rotation. To accomplish this, we mounted a barcode scanner to the back of the robot, pointed at a QR code taped to the battery. Each battery is given a unique identifier based on the year, and the scanned code is saved as metadata in each log file.

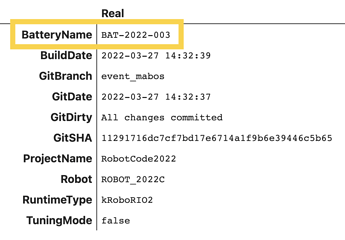
The scanner connects to the RIO over USB, and we wrote a BatteryTracker class to interface with it. While we haven’t had any catastrophic problems that would require this data, we can use it to compile more fun statistics (did you really not see that coming?)
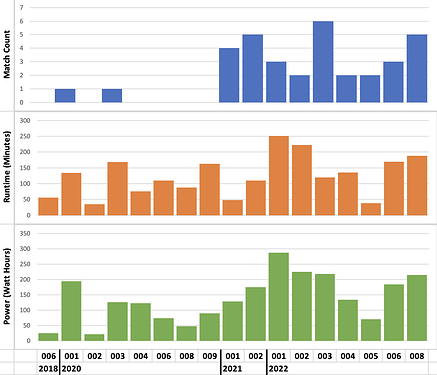
This graph includes all of the data from Granite State, Greater Boston, as well as practice and tuning sessions. We favor 2021 and 2022 batteries in match play, though it seems we have a bit of a grudge against battery 2022-005. We’ll have to make sure to put a few extra cycles on it before Houston…
How long is a match?
What a nice simple question that definitely doesn’t require dozens of log files to answer. It’s right there in the manual!

After any network latency and other complicating factors, we were curious about how many cycles the robot is actually enabled for. That’s especially important during auto; in our case, our five cargo auto is designed to use all 15 seconds to the fullest — any premature disables could risk preventing our final shots from being fired.
With 42 matches of data, here are the measured lengths of autonomous, teleoperated, and the disabled “gap” between them:
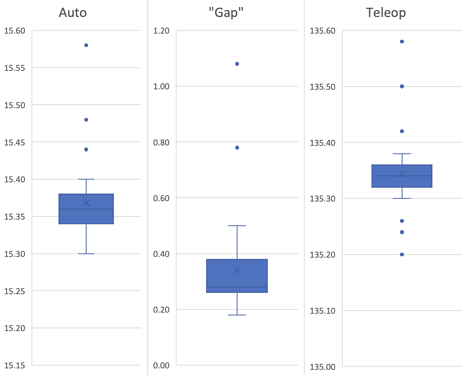
It seems that the FMS already accounts for the possibility of latency when enabling, consistently giving an extra 0.3-0.4 seconds in auto and teleop. We haven’t seen this documented anywhere yet, but hopefully it proves useful to someone.
We’re still hard at work on improvements for Houston, so keep an eye out for more posts in the near future. We’re happy to answer any questions.
